Darts (n) { k \(\leftarrow\) 0; for
i \(\leftarrow\) 1 to n do { x \(\leftarrow\) uniform(0, 1); y \(\leftarrow\) uniform(0, 1); //
随机产生点(x,y) if (\(x^2 + y^2 ≤ 1\))
then k++; // 圆内 } return 4k/n;
}
Darts (n) { k \(\leftarrow\) 0; for
i \(\leftarrow\) 1 to n do { x \(\leftarrow\) uniform(0, 1);
y \(\leftarrow\) x; // 随机产生点(x,y)
if (\(2x^2≤ 1\)) then k++; // \(x^2<=\frac{1}{2}\) } return 4k/n;
}
当x=y时, 随机产生点(x,y)都位于\(y=x,0\le x
\le 1\)的线段上,长度为1,而只有\(0\le
x \le \frac{\sqrt{2}}{2}\)范围内的点落在圆内,长度为\(\frac{\sqrt{2}}{2}\),所以算法估计的值为:
\[
4*\frac{k}{n}=4*\frac{\sqrt{2}}{2}=2\sqrt{2}
\]
实验代码
1 2 3 4 5 6 7 8 9 10 11 12 13
import random defDarts(n): k = 0 for i inrange(n): x = random.uniform(0, 1) y = x if x*x+y*y <= 1: k = k+1 return4*k/n
# 积分概率算法 defcalculate(func, n, a=0, b=1, c=0, d=1): k = 0 for i inrange(n): x = random.uniform(a, b) y = random.uniform(c, d) # 随机生成矩形内的点(x,y) if y <= func(x): k = k+1 S_1 = (b-a)*(d-c) # 计算矩形面积 return S_1*k/n
deffunc2(x): return math.exp(x)
print("e-1 = ", math.exp(1)-1) for n in [1000000, 10000000, 100000000]: print("n = {:<10d} result = {}".format( n, calculate(func2, n, 0, 1, 0, math.exp(1))))
实验结果
e-1 = 1.718281828459045 n = 1000000(1百万) result =
1.7169592244369005 (2精确度) n = 10000000 (1千万) result =
1.7181025337739504 (3精确度) n = 100000000 (1亿) result =
1.718124551856761 (3精确度)
# 用上述算法,估计整数子集1~n的大小,并分析n对估计值的影响。 from random import choice import math REPEAT_COUNT = 1000# 重复次数 defSetCount(X): k = 0 S = set() a = choice(X) whileTrue: k = k + 1 S.add(a) a = choice(X) if a in S: break return2 * k * k / math.pi
for n in [10, 1000, 10000, 1000000]: X = [] for i inrange(1, n + 1): X.append(i) sum = 0 Error_rate = 0.0 for i inrange(REPEAT_COUNT): sum += SetCount(X) Error_rate += math.fabs(SetCount(X) - n) / n # 计算每次估计值的误差 Estimate_N = sum/REPEAT_COUNT # 计算n的估计值 print("n = {:<10d} Estimate_N = {:<20.6f} Error_rate = {:.3%}".format( n, Estimate_N, Error_rate/n))
实验结果
计算每次估计误差,重复1000次,求最后的平均误差,结果如下:
image-20221115133201303
n 越大,每次估计误差越小,估值越准确。
Ex.6【P54】
分析dlogRH的工作原理,指出该算法相应的u和v
解: Sherwood 算法的一般过程:
将被解的实例变换到一个随机实例。 //预处理函数 u
用确定算法解此随机实例,得到一个解。
将此解变换为对原实例的解。 //后处理函数 v
dlogRH 对其中的 \(a=g^x \ mod \ p \
\)作随机预处理,得到与其对应的随机实例 c=u(x, r),并且对 c
使用确定性算法得到 y ,最后再把随机实例的结果 y 变换为输入实例 a 的解
x=v(y, r)。其中
\[
u: u(x, r) = log_{g,p} c = (r+x) mod (p-1) \\
v: v(y, r) = (y-r) mod (p-1)
\]
Ex.7【P67】 写一Sherwood算法C,与算法A, B,
D比较,给出实验结果。
解:
算法 C :在 B 的基础上修改,不是取前\(\sqrt n\)个元素作为基准,而是随机取\(\sqrt n\)个元素作为基准。
n = 10000 val = [] # 记录值数组 ptr = [] # 指针数组 head = 0# 链头 sa = [] sb = [] sc = [] sd = []
# 初始化静态链表数组 (链中指向数组编号从1开始 0表示结尾) for i inrange(0, n): val.append(i) random.shuffle(val) # 将序列的所有元素随机排序 该行注释表示基本有序的静态链表 # 将指针数组按照值从小到大链接 for i in val: if i != n - 1: ptr.append(val.index(i + 1)) # val.index() 查找数组中元素的序号 else: ptr.append(-1) head = val.index(0)
defsearch(x, i): """从位置i开始查找x,返回x所在位置序号和查找长度""" count = 0 while x > val[i]: i = ptr[i] count += 1 return i, count
defA(x): # o(n) return search(x, head)
defB(x): # o(sqrt(n)) i = head max = val[i] for j inrange(0, int(sqrt(n))): y = val[j] ifmax < y <= x: i = j max = y return search(x, i)
defC(x): # o(sqrt(n)) Sherwood i = head max = val[i] for j inrange(0, int(sqrt(n))): jj = random.randint(0, n - 1) y = val[jj] ifmax < y <= x: i = jj max = y return search(x, i)
defD(x): # o(n) count = 0 i = random.randint(0, n - 1) y = val[i] if x < y: return search(x, head) elif x > y: return search(x, ptr[i]) else: return i, 0
REPEAT_COUNT = 10000# 重复查找次数 for i inrange(REPEAT_COUNT): x = random.randint(0, n - 1) sa.append(A(x)[1]) sb.append(B(x)[1]) sc.append(C(x)[1]) sd.append(D(x)[1])
print("Algo A: average {:<10.3f} worst {:<10d}".format(sum(sa) / len(sa),max(sa))) print("Algo B: average {:<10.3f} worst {:<10d}".format(sum(sb) / len(sa),max(sb))) print("Algo C: average {:<10.3f} worst {:<10d}".format(sum(sc) / len(sa),max(sc))) print("Algo D: average {:<10.3f} worst {:<10d}".format(sum(sd) / len(sa),max(sd)))
# 写一算法,求n=12~20时最优的StepVegas值 import time from random import randint try_count = [] try_count.append(0) defqueensLV(stepVegas, try_, n, try_count): """贪心的LV算法(改进)""" col = set() diag45 = set() diag135 = set() k = 0# 行号 while k < n: if k == stepVegas: # 完全使用回溯法 return backtrace(k+1, try_, col, diag45, diag135, try_count) nb = 0# 计数器,nb值为(k+1)th皇后的open位置总数 j = 0# 记录随机摆放皇后的列位置 for i inrange(1, n+1): # i是列号, 试探(k+1,i)安全否 if (i notin col) and (i - k notin diag45) and (i + k notin diag135): # 列i对(k+1)th皇后可用,但不一定马上将其放在第i列 nb += 1 # 在nb个安全的位置上随机选择1个位置j放置之 if randint(1, nb) == 1: # 或许放在第i列 j = i # nb=0时无安全位置,第k+1个皇后尚未放好 if nb > 0: # 在所有nb个安全位置上,(k+1)th皇后选择位置j的概率为1/nb try_count[0] += 1# 1个皇后放好算是搜索树上的1个结点 k += 1# try[1..k+1]是(k+1)-promising try_[k] = j # 将选定的(k+1)th皇后放入 col.add(j) diag45.add(j - k) diag135.add(j + k) else: # 当前皇后找不到合适的位置 returnFalse
defbacktrace(k, try_, col, diag45, diag135, try_count): """传统的回溯法""" if k > n: # k表示行号 行号大于n表示皇后放置结束 returnTrue for j inrange(1, n+1): # 从当前列j起向后逐列试探 寻找安全列号 if (j notin col) and (j - k notin diag45) and (j + k notin diag135): # 找到安全列j 放置(k+1)th皇后 try_[k] = j col.add(j) diag45.add(j - k) diag135.add(j + k) try_count[0] += 1# 1个皇后放好算是搜索树上的1个结点 # 探索下一行 if backtrace(k+1, try_, col, diag45, diag135, try_count): returnTrue else: # 回溯 移去该行已放置的皇后 col.remove(j) diag45.remove(j - k) diag135.remove(j + k) returnFalse# 探索完所有列仍然没有符合要求的
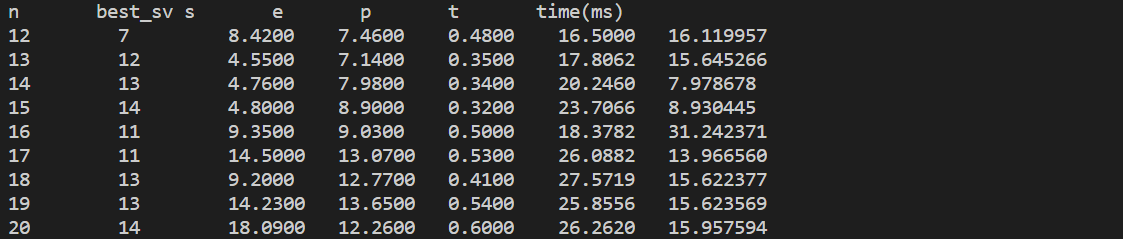
REPEAT_COUNT = 100# 运行次数 print("n\tbest_sv\ts\te\tp\tt\ttime(ms)") for n inrange(12, 21): best_sv = n best_s = 0 best_e = 0 best_p = 0 best_t = 0 best_time= 0 min_t = 1000000 for stepVegas inrange(0, n+1): p_count = 0# 成功次数 s_count = 0 e_count = 0 t1 = time.time() for _ inrange(REPEAT_COUNT): try_count[0] = 0 try_ = [-1for _ inrange(n+1)] # 序号1...k 初始化为-1 if queensLV(stepVegas, try_, n, try_count): p_count += 1 s_count += try_count[0] else: e_count += try_count[0] t2 = time.time() total_time = (t2-t1)*1000 s = s_count/REPEAT_COUNT # 成功时搜索的结点的平均数 e = e_count/REPEAT_COUNT # 失败时搜索的结点的平均数 p = p_count/REPEAT_COUNT # 成功的概率(一次成功) t = s+(1-p)*e/(p+0.0001) # 搜索的平均节点数 if t < min_t: min_t = t best_sv = stepVegas # 取最小化t的stepVegas best_s = s best_e = e best_p = p best_t = t best_time = total_time # print("{:<10d}{:<10d}{:<10.4f}{:<10.4f}{:<10.4f}{:<10.4f}{:<15.6f}".format( # n, stepVegas, s, e, p, t, total_time)) print("{:<10d}{:<10d}{:<10.4f}{:<10.4f}{:<10.4f}{:<10.4f}{:<15.6f}".format( n, best_sv, best_s, best_e, best_p, best_t, best_time))
实验结果
image-20221115220055192
Ex.10【147】
PrintPrimes{ //打印1万以内的素数 print 2,3; n ←5; repeat if
RepeatMillRab(n,$ _{}{n} $) then print n; n ←n+2; until n=10000; }
# RepeatMillRab素性测试与确定性算法相比较,并给出100~10000以内错误的比例。 from math import sqrt, log10 from random import randint
defBtest(a, n): """返回真说明n是强伪素数或素数""" s = 0 t = n - 1# t开始为偶数 while t % 2 == 0: s = s + 1 t = t // 2 x = a ** t % n if x == 1or x == n - 1: returnTrue for i inrange(1, s): x = x ** 2 % n if x == n - 1: returnTrue returnFalse
defMillRab(n): """Miller-Rabin测试:奇n>4 返回真时表示素数 假表示合数""" a = randint(2, n - 2) return Btest(a, n) # 测试n是否为强伪素数
defRepeatMillRab(n, k): """重复调用k次之后返回true""" for i inrange(k): if MillRab(n) == False: returnFalse# 一定是合数 returnTrue# 高概率为素数
defis_prime(n): """确定性算法确定是否为素数""" for i inrange(2, int(sqrt(n)) + 1): if n % i == 0: returnFalse returnTrue
start = 100 end = 10000 REPEAT_COUNT = 10# 重复次数 for k inrange(1, 6): error = 0 for _ inrange(REPEAT_COUNT): for i inrange(start, end): if RepeatMillRab(i, k) != is_prime(i): error += 1 error /= REPEAT_COUNT # 平均错误次数 print("k = {:<4d} error times = {:<10.2f} error rate = {:<10.6f}".format( k, error, error/(end-start)))